Ry Cutter

A PhD in Astrophysics turned Data Scientist and Software Engineer, driven by a passion for science communication and innovative problem-solving.
Multidisciplinary:
- Lead Innovation Data Scientist
- Customer Insights and Behaivour Analyst
- Machine Learning Engineer
Machine Learning, Embedded ML, Software/Firmware Engineering, Automation, Python, Time Series, Forecasting, NLP, Data Visualisation, Experimental Design, Physics, Statistics, Wearable Tech, Connectivity, Human Factors, UI/UX
View My LinkedIn Profile
My CV
Web Scraping With Natural Language Processing
Amazon Review Webscraper
One of the first challenges I was given working in [current company] was to quickly determine sentiment of amazon purchases. I started by building a generalised web scraper (All the scraping code at the bottom of the page 😉) and using that to mine the data.
All the content of the review is captured; including date it was written, product rating, images, URL of the review, if the purchase is verrfied, and the product variant. This means you can filter your search by more than just product.
Generally speaking, sentiment can be determined by star ratings. All >1 star ratings match their expected sentiment (people clicking on stars do it on purpose, but a lot of people forget to rate and the default is 1 star). This meant that a little sentiment analysis has to be done on 1 star reviews to make sure they’re intnetionally 1 star.
After the analysis has been done word clouds can be built to establish key themes in the ratings.


These word clouds have been moderated slightly to avoid giving away any top secret info!
Using the data collected, I was able to inform multiple pillars of the company, from R&D to Marketing! This helped tailor advertising strategy throughout the year and revealed pain points we can fix (one was design ergonomics, the other was lowering the weight of the product).
In addition to scoping sentiment and product improvement. This technique has also proven benefitial to fight patent infringments or competitor claims quickly. One can scour reviews for comments relating to a technology or product for proof to counter IP aguments. I successfully shot down two competitor patents attempting to claim a technology my company had be using for years, and prevented us from getting sued once; using the reviews as evidence a technology already existed in our product portfolio before the publication of the infringed patent.
The Patent Sentinel
In a similar vein to the amazon web-scraper, the patent sentinal screens the IP Office for patentes that contain key words relevant to the industry or published by lead competitors. The scrape will flag any “high importance” patents in an email and also writes all of the patents (published or otherwise) and their information to an excel sheet. (I personally did not want to use excel, but it was my teams medium of choice… democracy.) Graphs are automatically generated detailing opponent patent history and anticipated future submission frequency.
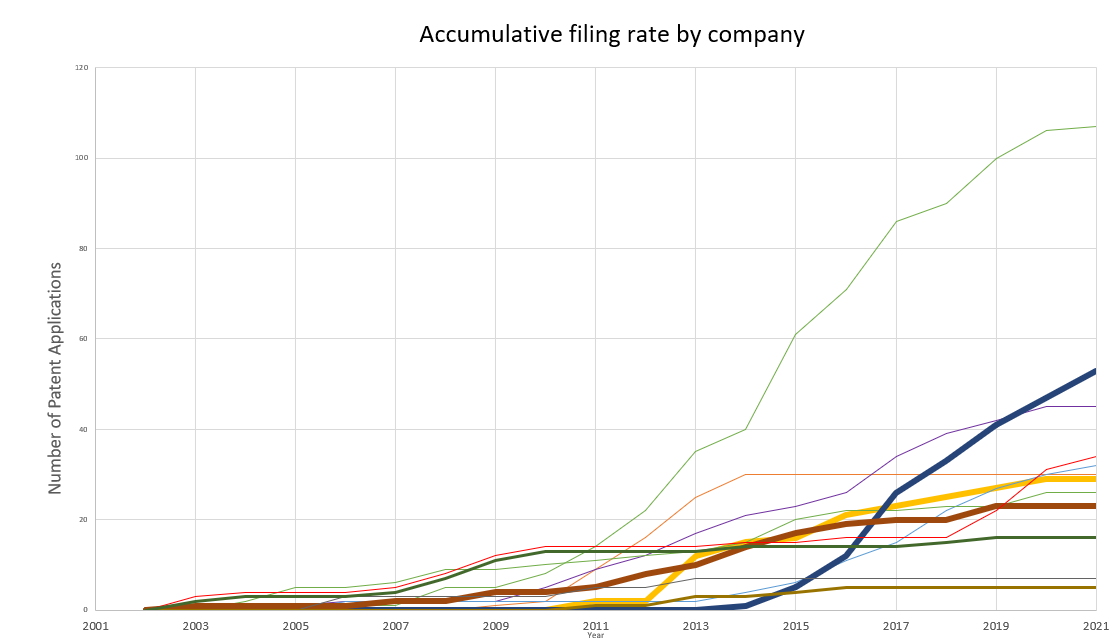
This was a useful way to communicate to execs how our IP capture efforts were going in comparison to competitors and also to demonstrate trends in patent areas.
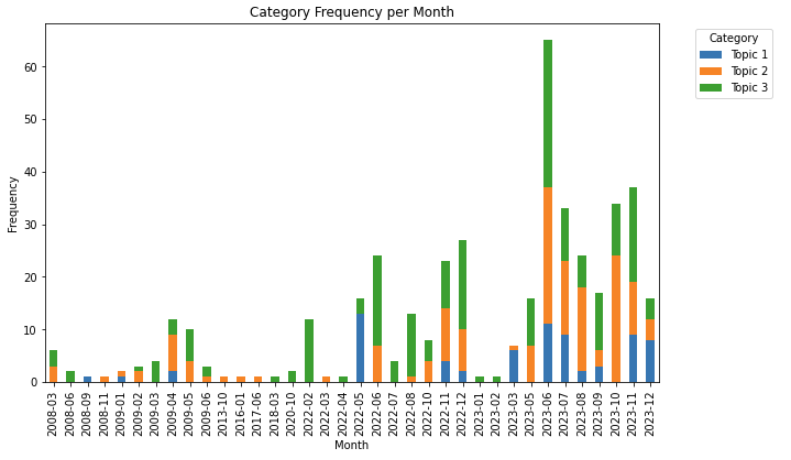
Topic Modelling to Determine Competitor Priorities.
Some of the things that one can scrape include: claims, abstracts, titles, and owner. Given that my current company’s main competitor is churning out 50 patents a month, dedicating resource to following their patent history and mapping their direction is expensive. Using Latent Dirichlet Allocation (LDA) on the titles, abstracts, and claims. I was able to group competitor patents into different and distint themes. Using publication frequency, we can quickly see what research they are prioritising and pivot our research strategies around competitor behaviour.
The Amazon Code
import random
import requests
from bs4 import BeautifulSoup
from selectorlib import Extractor
import requests
import json
from time import sleep
import csv
from dateutil import parser as dateparser
# Create an Extractor by reading from the YAML file
e = Extractor.from_yaml_file('selectors.yml')
user_agent_list = [
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_5) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/13.1.1 Safari/605.1.15',
'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:77.0) Gecko/20100101 Firefox/77.0',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.97 Safari/537.36',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.15; rv:77.0) Gecko/20100101 Firefox/77.0',
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.97 Safari/537.36',
] #List of Agents are needed so Amazon doesn't notice we're queerying so much (update list monthly need about 10 usually)
def scrape(url):
headers = {
'authority': 'www.amazon.com',
'pragma': 'no-cache',
'cache-control': 'no-cache',
'dnt': '1',
'upgrade-insecure-requests': '1',
'user-agent': random.choice(user_agent_list),
'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
'sec-fetch-site': 'none',
'sec-fetch-mode': 'navigate',
'sec-fetch-dest': 'document',
'accept-language': 'en-GB,en-US;q=0.9,en;q=0.8',
}
# Download the page using requests
print("Downloading %s"%url)
r = requests.get(url, headers=headers)
# Simple check to check if page was blocked (Usually 503)
if r.status_code > 500:
if "To discuss automated access to Amazon data please contact" in r.text:
print("Page %s was blocked by Amazon. Please try using better proxies\n"%url)
else:
print("Page %s must have been blocked by Amazon as the status code was %d"%(url,r.status_code))
return None
#Pass the HTML of the page and create
if "To discuss automated access to Amazon data please contact api-services-support@amazon.com" not in r.text:
return e.extract(r.text)
else:
print('\n!!!\nRETRY\n!!!\n')
return(scrape(url))
def getAmazonReviewData(_dict, url):
with open(_dict[url]+'.csv','w', encoding='utf-8') as outfile:
writer = csv.DictWriter(outfile, fieldnames=["title","content","date","variant","images","verified","author","rating","product","url"],quoting=csv.QUOTE_ALL)
writer.writeheader()
for i in range(1000):
sleep(5) #Sleep for five seconds so the servers don't flag IP for scraping
url_n = url+str(i+1)
data = scrape(url_n)
if data['reviews'] is None:
break
else:
print('Good!')
if data:
for r in data['reviews']:
r["product"] = data["product_title"]
r['url'] = url
if 'verified' in r:
if r['verified'] is None:
r['verified'] = 'No'
if 'Verified Purchase' in r['verified']:
r['verified'] = 'Yes'
else:
r['verified'] = 'Yes'
if r['rating'] is None:
r['rating'] = 0
else:
r['rating'] = r['rating'].split(' out of')[0]
date_posted = r['date'].split('on ')[-1]
if r['images']:
r['images'] = "\n".join(r['images'])
r['date'] = dateparser.parse(date_posted).strftime('%d %b %Y')
try:
writer.writerow(r)
except:
continue
Then run the code by using:
url_dict = {
"https://www.amazon.co.uk/product-reviews/B08373WJYC/ref=cm_cr_arp_d_paging_btm_next_2?ie=UTF8&reviewerType=all_reviews&pageNumber=" : "Gumball",
"https://www.amazon.co.uk/Snacking-Selection-Gherkins-Original-Flavours/product-reviews/B0C8ZGQFQ3/ref=cm_cr_arp_d_paging_btm_next_2?ie=UTF8&reviewerType=all_reviews&pageNumber=":"Pickle Selects",
"https://www.amazon.co.uk/toymany-Realistic-Figurines-Antarctic-Different/product-reviews/B0CFPL1FKN/ref=cm_cr_arp_d_paging_btm_next_2?ie=UTF8&reviewerType=all_reviews&pageNumber=":"Penguins"
}
for k in url_dict.keys():
getAmazonReviewData(url_dict, k)
Note: user_agent_list will need to be updated so amazon can’t track your scrape.
selectors.yaml file
product_title:
css: 'h1 a[data-hook="product-link"]'
type: Text
reviews:
css: 'div.review div.a-section.celwidget'
multiple: true
type: Text
children:
title:
css: a.review-title
type: Text
content:
css: 'div.a-row.review-data span.review-text'
type: Text
date:
css: span.a-size-base.a-color-secondary
type: Text
variant:
css: 'a.a-size-mini'
type: Text
images:
css: img.review-image-tile
multiple: true
type: Attribute
attribute: src
verified:
css: 'span[data-hook="avp-badge"]'
type: Text
author:
css: span.a-profile-name
type: Text
rating:
css: 'div.a-row:nth-of-type(2) > a.a-link-normal:nth-of-type(1)'
type: Attribute
attribute: title
next_page:
css: 'li.a-last a'
type: Link